LEAP: Liberate Sparse-view 3D Modeling
from Camera Poses
Hanwen Jiang Zhenyu Jiang Yue Zhao Qixing Huang
The University of Texas at Austin
ICLR 2024
Paper | Code
TL;DR: NeRF from sparse (2~5) views without camera poses, runs in a second, and generalizes to novel instances.
Real-World Demo
|
Are camera poses necessary for multi-view 3D modeling? Existing approaches predominantly assume access to accurate camera poses. While this assumption might hold for dense views, accurately estimating camera poses for sparse views is often elusive. Our analysis reveals that noisy estimated poses lead to degenerated performance for existing sparse-view 3D modeling methods. To address this issue, we present LEAP, a novel pose-free approach, therefore challenging the prevailing notion that camera poses are indispensable. LEAP discards pose-based operations and learns geometric knowledge from data. LEAP is equipped with a neural volume, which is shared across scenes and is parameterized to encode geometry and texture priors. For each incoming scene, we update the neural volume by aggregating 2D image features in a feature-similarity-driven manner. The updated neural volume is decoded into the radiance field, enabling novel view synthesis from any viewpoint. On both object-centric and scene-level datasets, we show that LEAP significantly outperforms prior methods when they employ predicted poses from state-of-the-art pose estimators. Notably, LEAP performs on par with prior approaches that use ground-truth poses while running 400x faster than PixelNeRF. We show LEAP generalizes to novel object categories and scenes, and learns knowledge closely resembles epipolar geometry. |
Overview
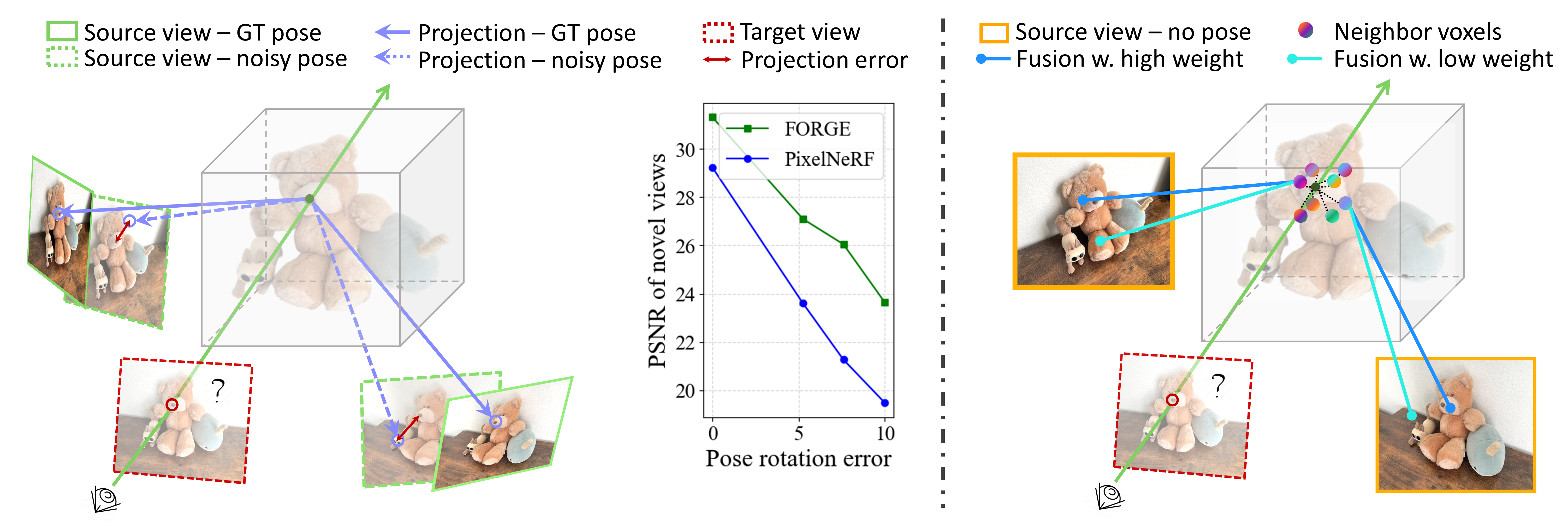
|
|
(Left) Prior works use poses-based operations, i.e., projection, to map 2D image information into the 3D domain. However, under inaccurate poses, the 2D-3D association will be wrong, leading to incorrect 3D features and degenerated performance. (Right) In contrast, LEAP uses attention to assign weights to all 2D pixels adaptively. The operation is not reliant on camera poses, enabling LEAP directly perform inference on unposed images. To initialize the features of 3D points, LEAP introduces a parametrized neural volume, which is shared across all scenes. The neural volume is trained to encode geometry and texture priors. For each incoming scene, the neural volume gets updated by querying the 2D image features and decodes the radiance field. For each 3D query point on a casting ray, its features are interpolated from its nearby voxels. |
Reconstruction Results
Compare with Prior Arts
|
LEAP outperforms prior works that use state-of-the-art pose estimators, as well as pose-free SRT and single-view-based Zero123. LEAP performs on par with prior works that use ground-truth poses. 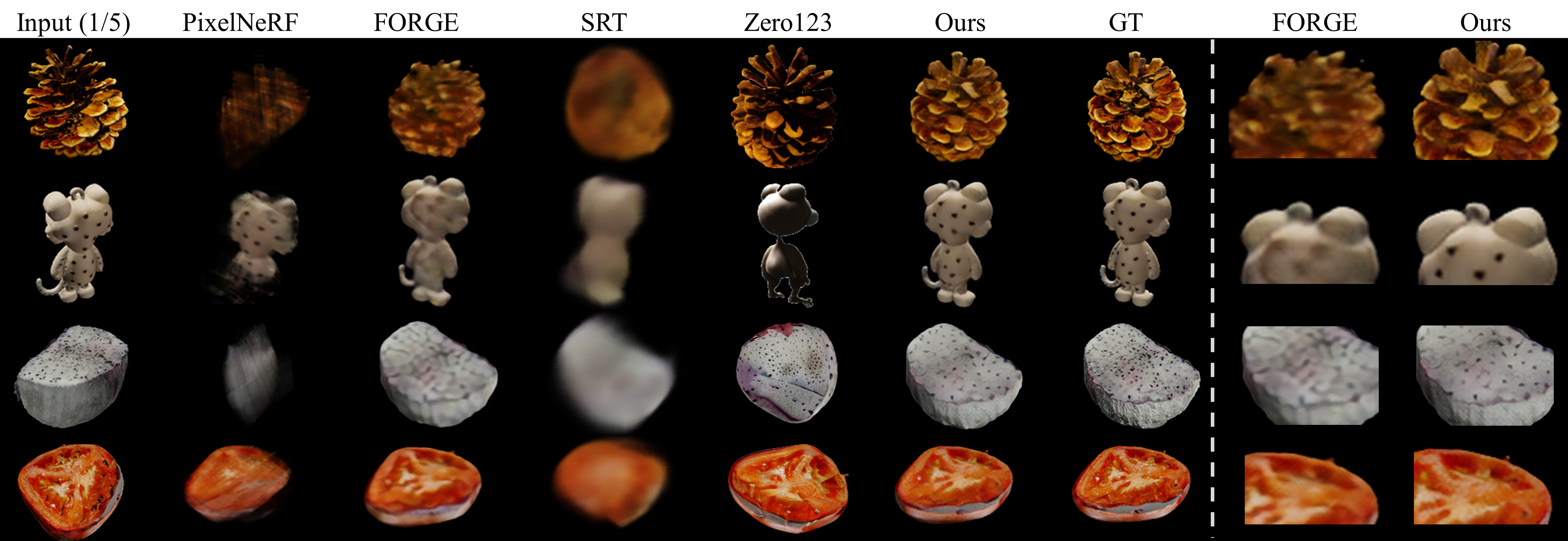
|
Transfer Knowledge to Scene-level Dataset
|
As a pose-free method that learns geometric knowledge from data, LEAP generally requires larger training data. However, we find a pre-trained LEAP on object-centric dataset can transfer to scene-level, with only tens of training sample. This implies that LEAP learns general geometric knowledge. The performance on the DTU dataset is comparable to SPARF, which requires dense correspondence as inputs and per-scene training of 1 day. 
|
Interpret LEAP
Learned Geometric Knowledge
|
We input images of a small dot (in orange boxes), and the visualization of the reconstructed neural volume shows consistency with the epipolar lines of the small dot on target views. This implies LEAP mapps a 2D point as its 3D reprojection ray segment even though there are no reprojection operations. 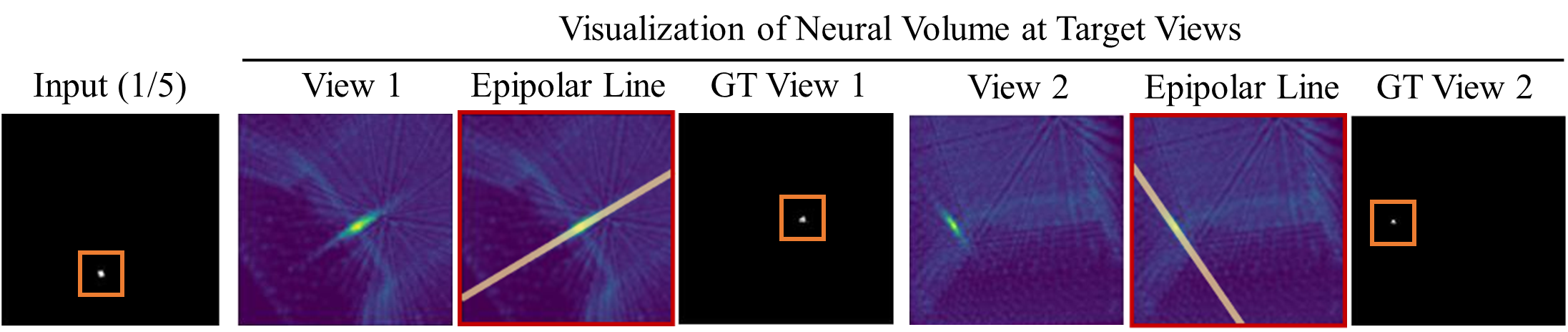
|
2D-2D Attention
|
The query pixel (shown in red) of the canonical view attends to the corresponding regions in canonical views. 
|
Neural Volume
|
We analyze the neural volume by slicing it and using PCA for visualization. The learned neural volume encodes the mean shape in high-dimensional space. After aggregating information from 2D images, it encodes the surface of the object in a coarse-to-fine manner. 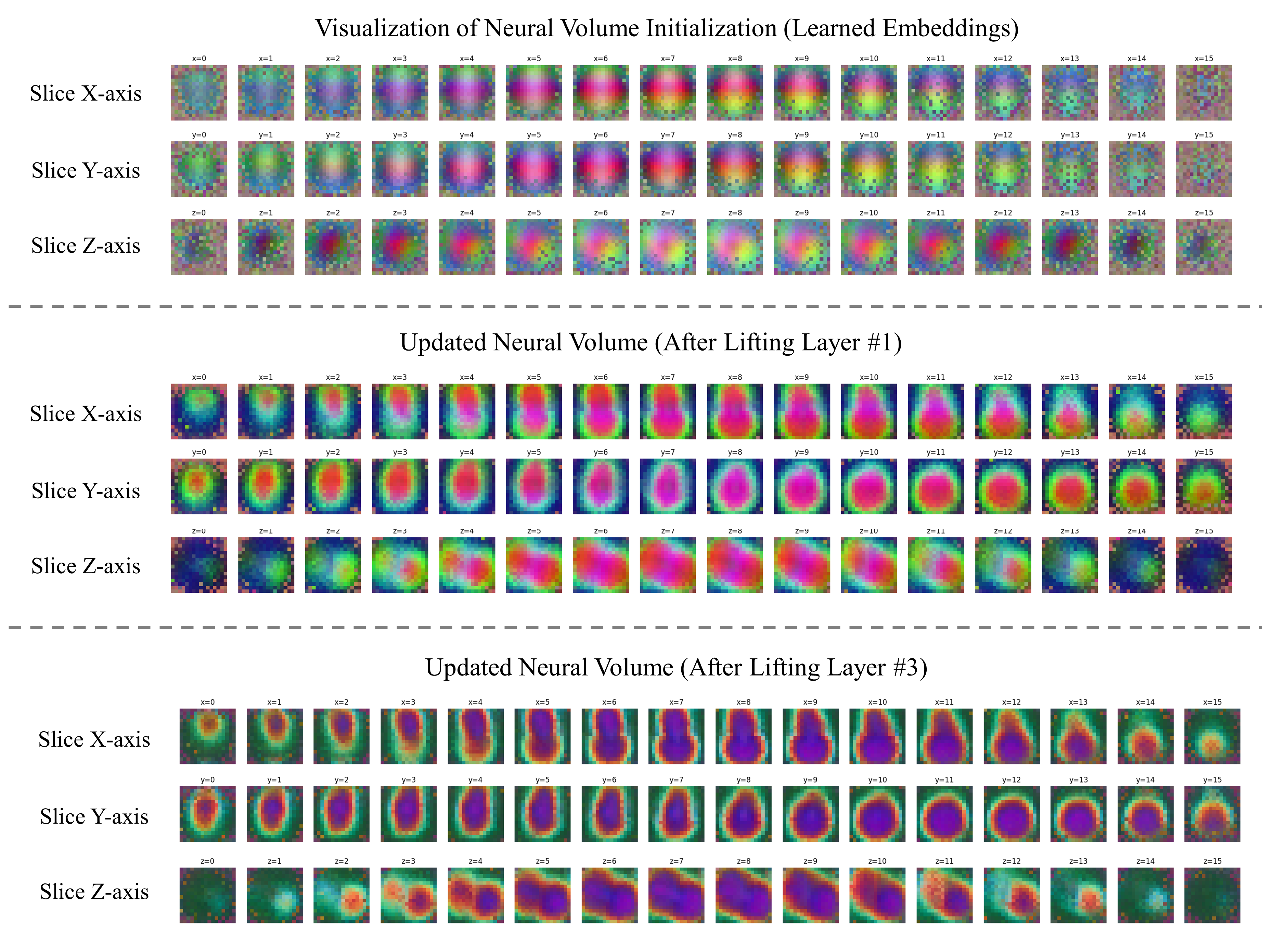
|
3D-2D Attention
|
We visualize the 3D-2D attention weights for selected voxels. We show that on-surface voxels attend to specific 2D regions and the attention demonstrates to be smooth on neighbour on-surface voxels. The attention of non-surface voxels diffuses. 
|
Related Project and Acknowledgement
|
FORGE: Sparse-view reconstruction by leveraging the syngergy between shape and pose. Cross-view Transformers: A cross-view transformer that maps unposed images (while with fixed poses) to a representation in another domain. We thank Brady Zhou for his inspiring cross-view transformers, and we thank Shuhan Tan for proof-reading the paper. |
Citation
|