Hanwen Jiang 江翰文
 Blog
Blog

About me
I am a Research Scientist at Adobe Research. My research focuses on building scalable and long-context visual intelligence and multi-modal systems with semantic and physical knowledge.
I previously worked on 3D vision for building spatial-aware visual intelligence, with scalable model architectures, data pipelines, and learning objectives.
I received my Ph.D. in CS at UT Austin, honored to be advised by Prof. Qixing Huang and Prof. Georgios Pavlakos. I received an M.S. in CS from UCSD in 2021, fortunately advised by Prof. Xiaolong Wang.
Publications
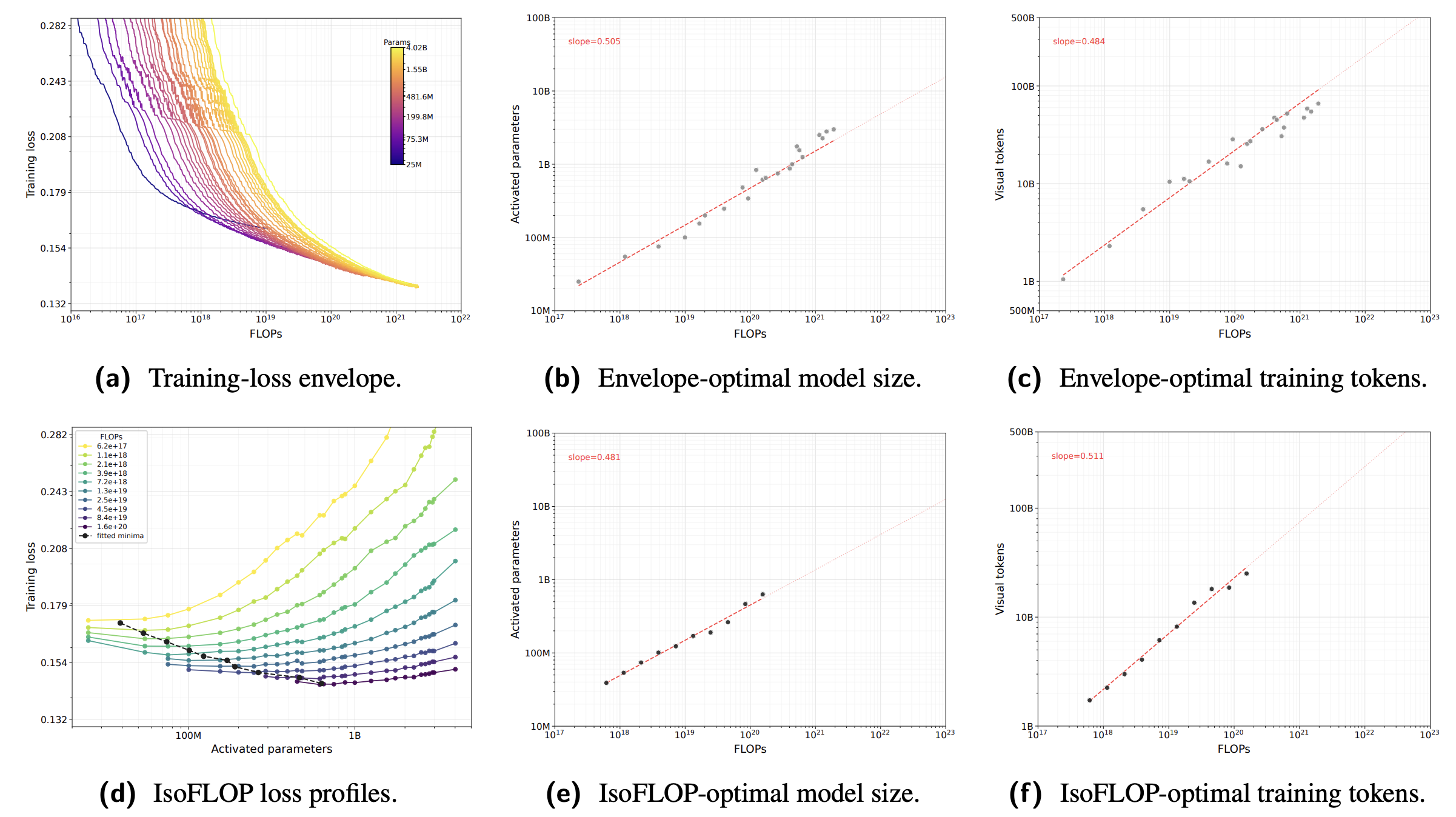
Wonder: Video World Model Done Better
Jiacong Xu*, Hanwen Jiang, Zhixin Shu, Kalyan Sunkavalli, Vishal M. Patel, Yiqun Mei*
Technical Report, 2026
Auto3R: Automated 3D Reconstruction and Scanning via Data-driven Uncertainty Quantification
Chentao Shen, Sizhe Zheng, Bingqian Wu, Yaohua Feng, Yuanchen Fei, Mingyu Mei, Hanwen Jiang, Xiangru Huang
ECCV, 2026
MotiMotion: Motion-Controlled Video Generation with Visual Reasoning
Lee Hsin-Ying, Hanwen Jiang, Yiqun Mei, Jing Shi, Ming-Hsuan Yang, Zhixin Shu
ICML, 2026
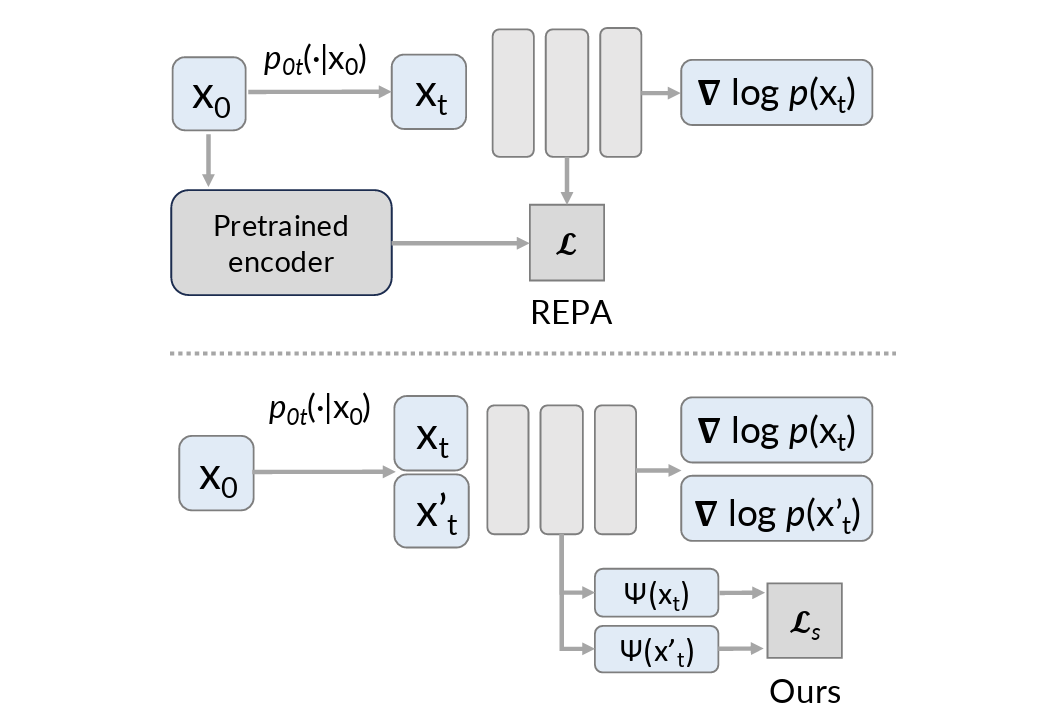
Revisiting Spectral Representations in Generative Diffusion Models
Yuehao Wang, Peihao Wang, Hanwen Jiang, Ziyi Yang, Qixing Huang, Zhangyang Wang
ICML, 2026
E-RayZer: Self-supervised 3D Reconstruction as Spatial Visual Pre-training
Qitao Zhao, Hao Tan, Qianqian Wang, Sai Bi, Kai Zhang, Kalyan Sunkavalli, Shubham Tulsiani*, Hanwen Jiang*
CVPR, 2026 (Highlight)
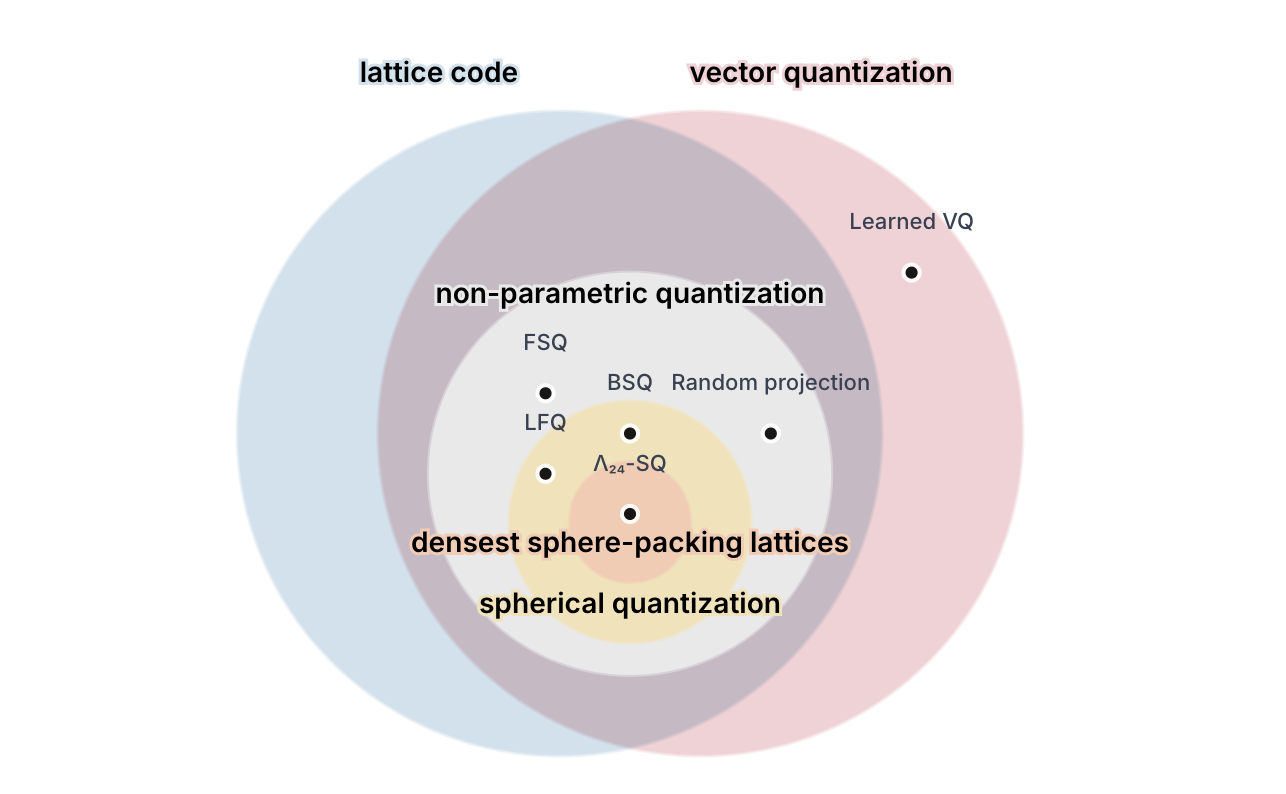
Spherical Leech Quantization for Visual Tokenization and Generation
Yue Zhao, Hanwen Jiang, Zhenlin Xu, Chutong Yang, Ehsan Adeli, Philipp Krahenbuhl
CVPR, 2026 (Highlight)
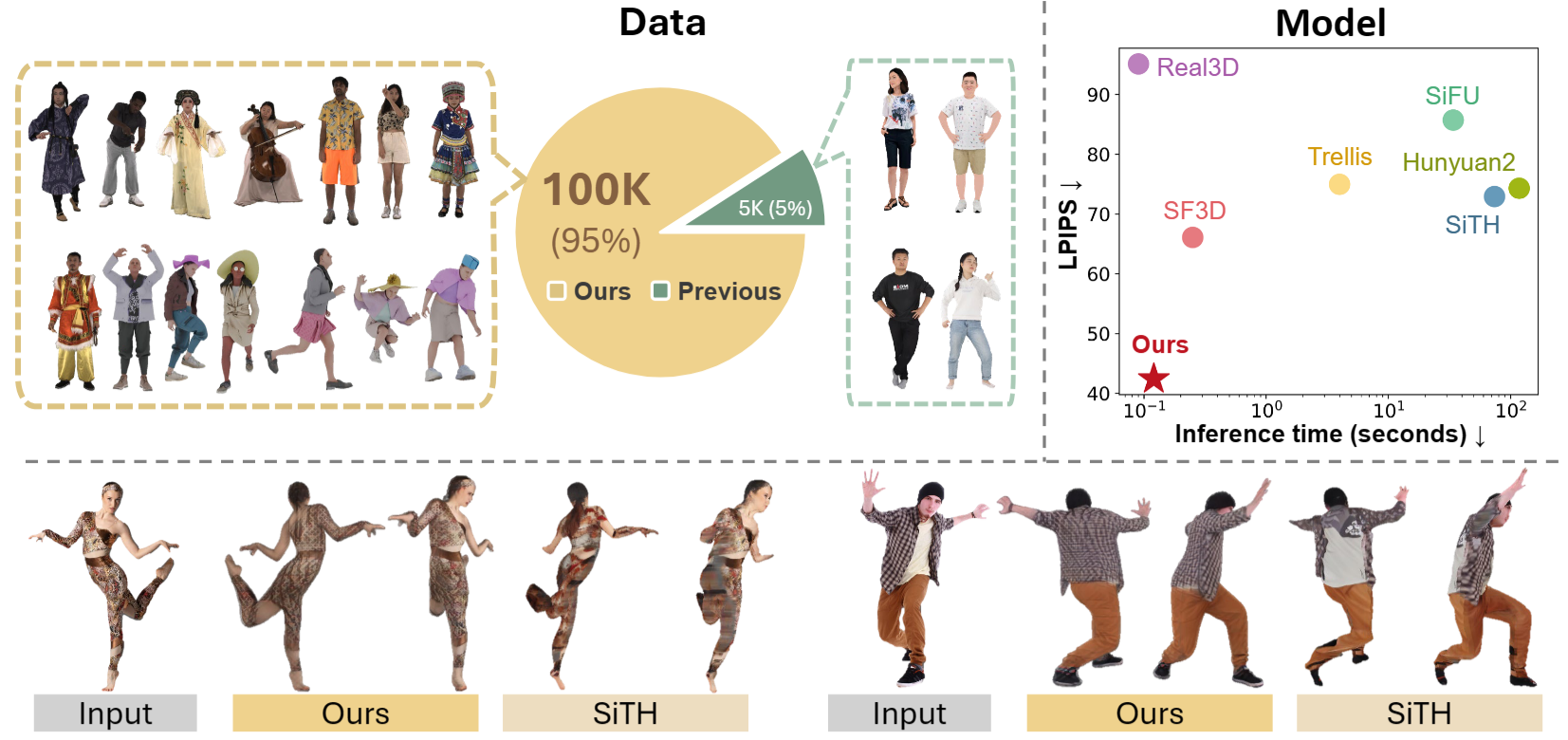
HumanNOVA: Photorealistic, Universal and Rapid 3D Human Avatar Modeling from a Single Image
Hezhen Hu, Wangbo Zhao, Lanqing Guo, Hanwen Jiang, Jonathan C. Liu, Zhiwen Fan, Kai Wang, Zhangyang Wang, Georgios Pavlakos
CVPR, 2026 (Highlight)
WorldReel: 4D Video Generation with Consistent Geometry and Motion Modeling
Shaoheng Fang, Hanwen Jiang, Yunpeng Bai, Niloy J. Mitra, Qixing Huang
CVPR, 2026
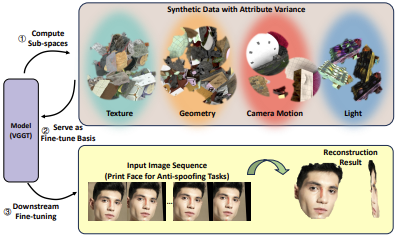
Mining Attribute Subspaces for Efficient Fine-tuning of 3D Foundation Models
Yu Jiang, Hanwen Jiang, Ahmed Abdelkader, Wen-Sheng Chu, Brandon Y. Feng, Zhangyang Wang, Qixing Huang
CVPR, 2026
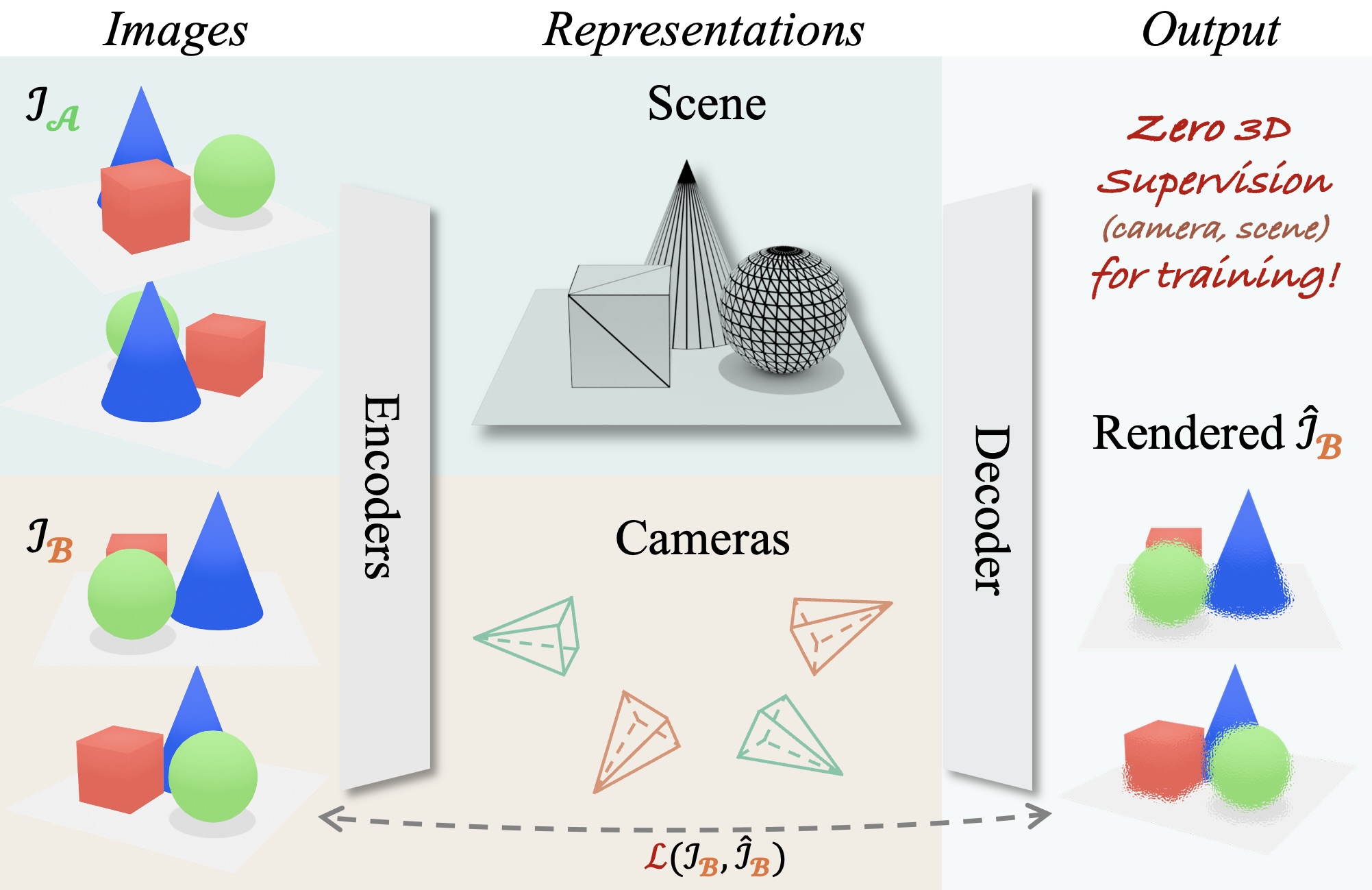
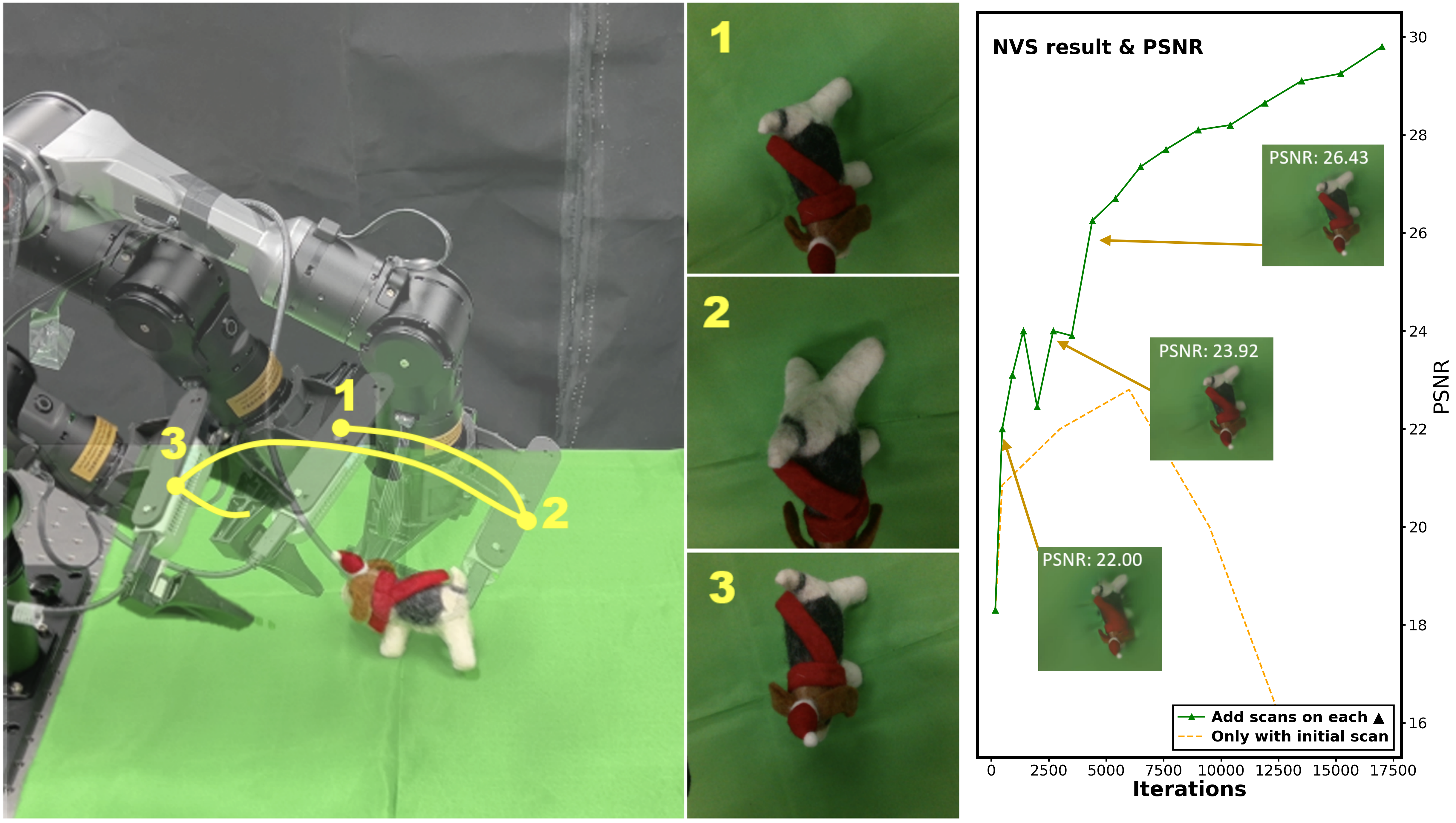
RayZer: A Self-supervised Large View Synthesis Model
Hanwen Jiang, Hao Tan, Peng Wang, Haian Jin, Yue Zhao, Sai Bi, Kai Zhang, Fujun Luan, Kalyan Sunkavalli, Qixing Huang, Georgios Pavlakos
ICCV, 2025 (Best Student Paper Honorable Mention, Best Paper Candidate, Oral Presentation)

Real3D: Scaling Up Large Reconstruction Models with Real-World Images
Hanwen Jiang, Qixing Huang, Georgios Pavlakos
ICCV, 2025

MegaSynth: Scaling Up 3D Scene Reconstruction with Synthesized Data
Hanwen Jiang, Zexiang Xu, Desai Xie, Ziwen Chen, Haian Jin, Fujun Luan, Zhixin Shu, Kai Zhang, Sai Bi, Xin Sun, Jiuxiang Gu, Qixing Huang, Georgios Pavlakos, Hao Tan
CVPR, 2025

LVSM: A Large View Synthesis Model with Minimal 3D Inductive Bias
Haian Jin, Hanwen Jiang, Hao Tan, Kai Zhang, Sai Bi, Tianyuan Zhang, Fujun Luan, Noah Snavely, Zexiang Xu
ICLR, 2025 (Oral Presentation)
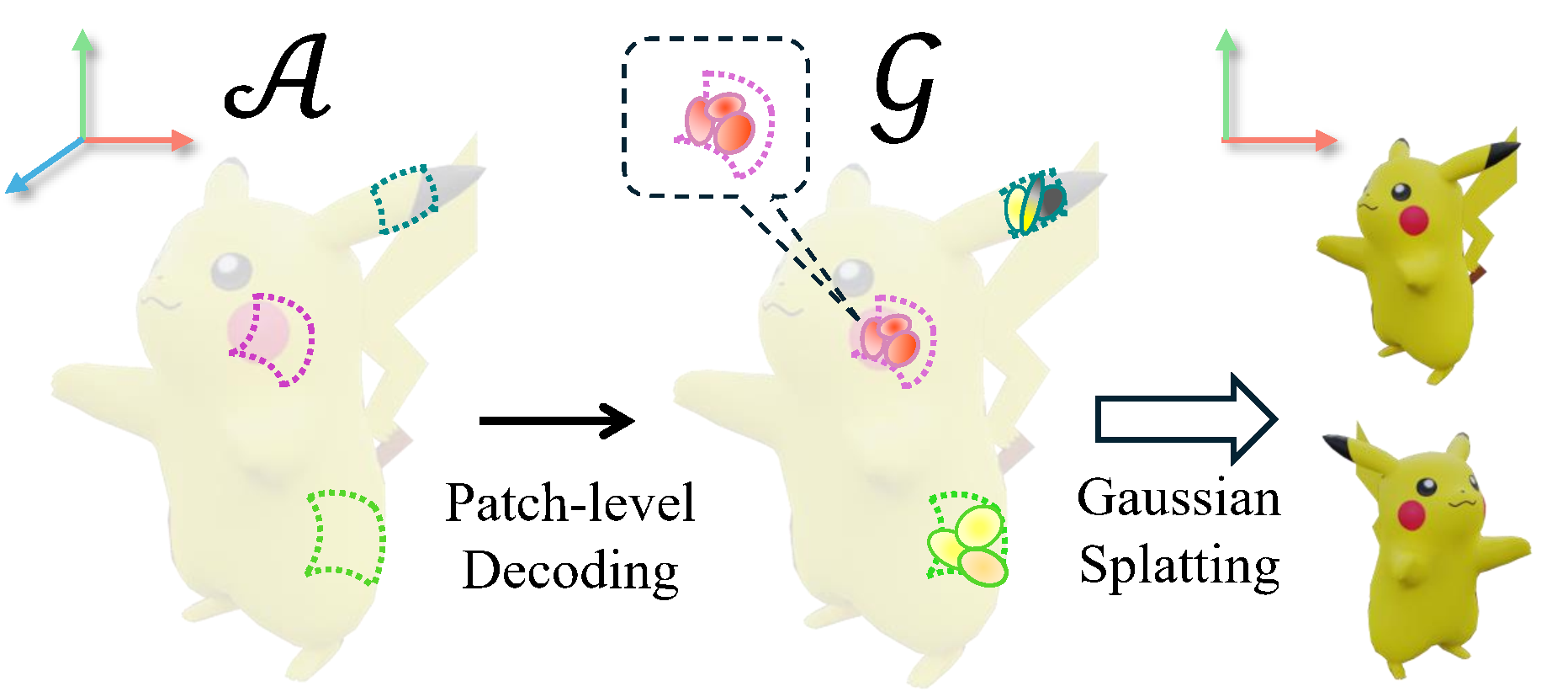
Atlas Gaussians Diffusion for 3D Generation
Haitao Yang*, Yuan Dong*, Hanwen Jiang, Dejia Xu, Georgios Pavlakos, Qixing Huang
ICLR, 2025 (Spotlight)
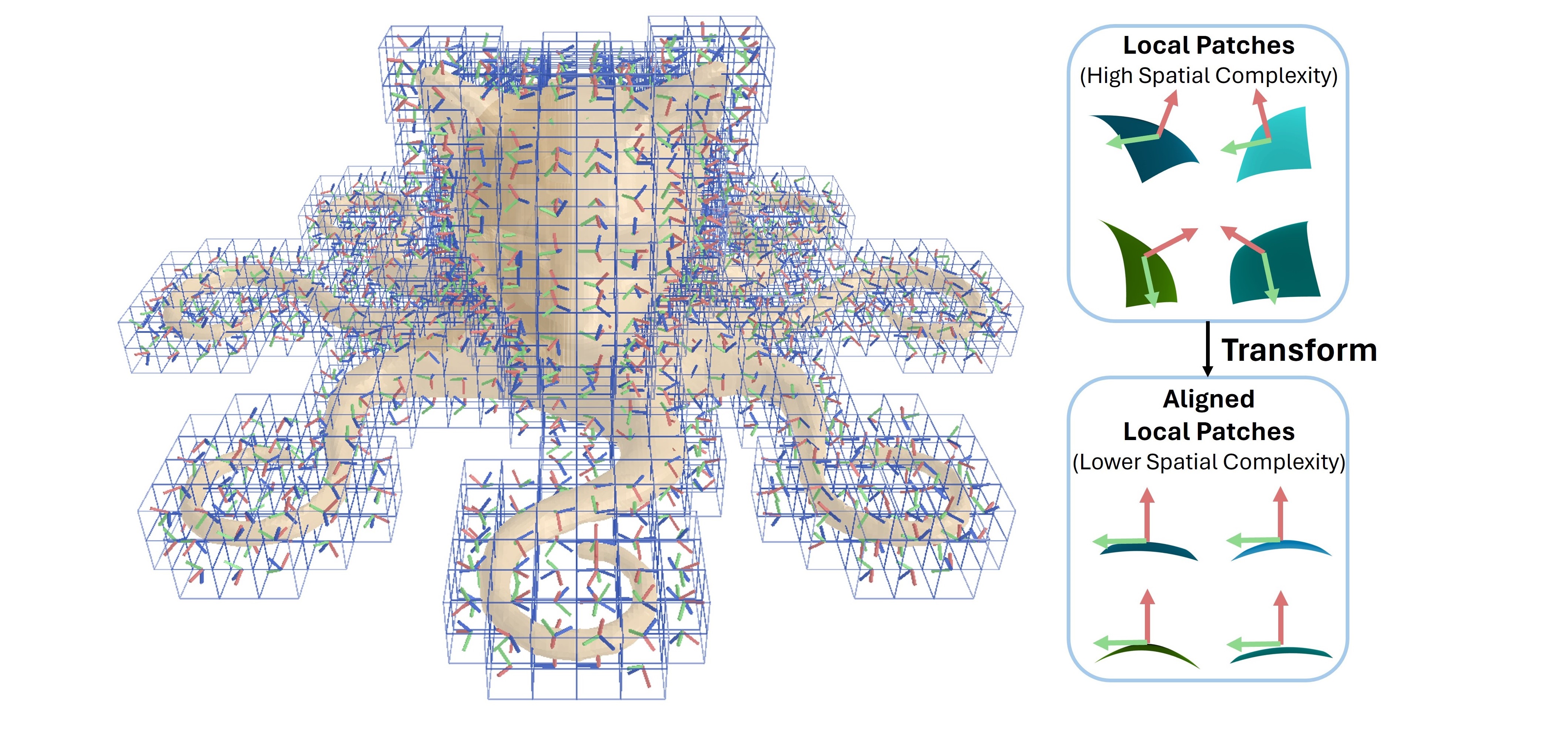
CoFie: Learning Compact Neural Surface Representations with Coordinate Fields
Hanwen Jiang, Haitao Yang, Georgios Pavlakos, Qixing Huang
NeurIPS, 2024
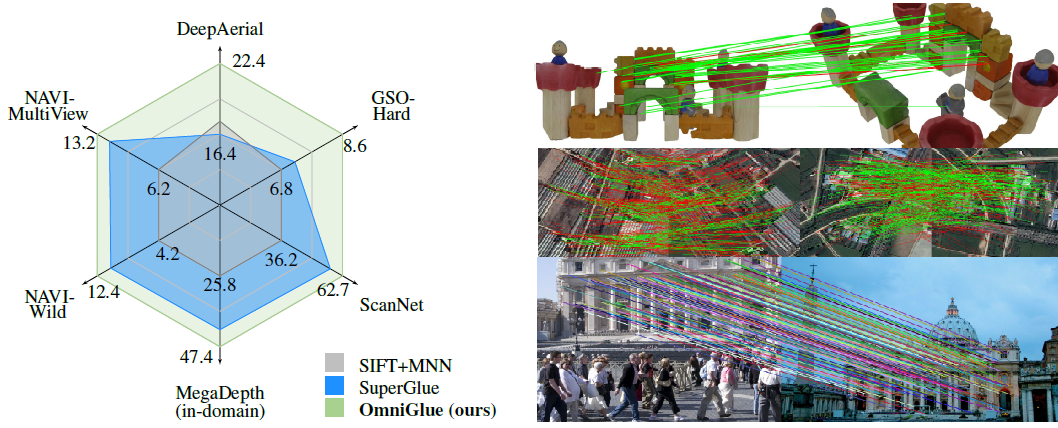
OmniGlue: Generalizable Feature Matching with Foundation Model Guidance
Hanwen Jiang, Arjun Karpur, Bingyi Cao, Qixing Huang, Andre Araujo
CVPR, 2024

LEAP: Liberate Sparse-view 3D Modeling from Camera Poses
Hanwen Jiang, Zhenyu Jiang, Yue Zhao, Qixing Huang
ICLR, 2024

Doduo: Learning Dense Visual Correspondence from Unsupervised Semantic-Aware Flow
Zhenyu Jiang, Hanwen Jiang, Yuke Zhu
ICRA, 2024

Few-View Object Reconstruction with Unknown Categories and Camera Poses
Hanwen Jiang, Zhenyu Jiang, Kristen Grauman, Yuke Zhu
3DV, 2024 (Best Paper Candidate)

Single-Stage Visual Query Localization in Egocentric Videos
Hanwen Jiang, Santhosh Ramakrishnan, Kristen Grauman
NeurIPS, 2023 (Winner of Ego4D VQ2D Challenge)

DexMV: Imitation Learning for Dexterous Manipulation from Human Videos
Yuzhe Qin*, Yueh-Hua Wu*, Shaowei Liu, Hanwen Jiang, Ruihan Yang, Yang Fu, Xiaolong Wang
ECCV, 2022

Hand-Object Contact Consistency Reasoning for Human Grasps Generation
Hanwen Jiang*, Shaowei Liu*, Jiashun Wang, Xiaolong Wang
ICCV, 2021 (Oral Presentation)

Semi-Supervised 3D Hand-Object Poses Estimation with Interactions in Time
Shaowei Liu*, Hanwen Jiang*, Jiarui Xu, Sifei Liu, Xiaolong Wang
CVPR, 2021
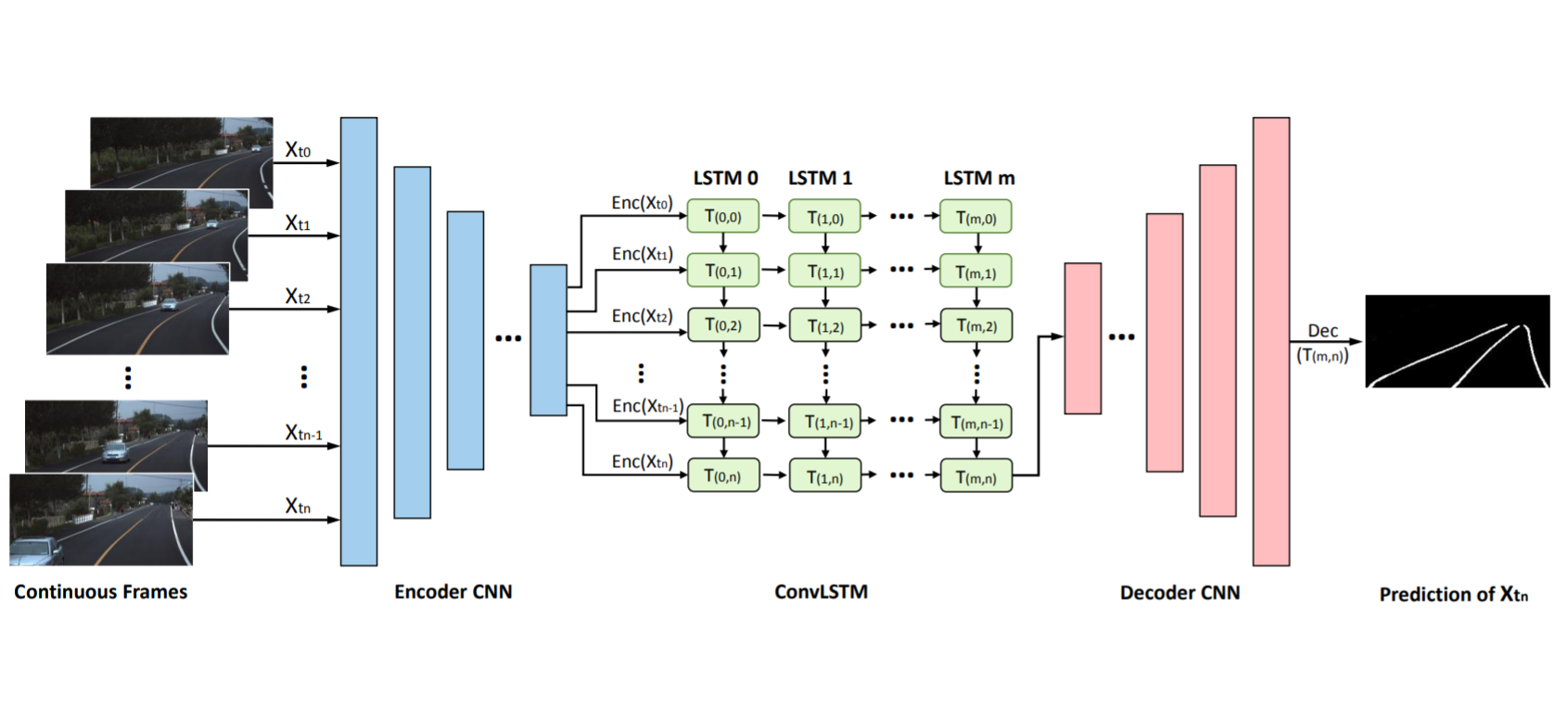
Robust Lane Detection from Continuous Driving Scenes Using Deep Neural Networks
Qin Zou, Hanwen Jiang, Qiyu Dai, Yuanhao Yue, Long Chen, Qian Wang
IEEE TVT, 2020. (IEEE Best Land Transportation Paper Award)
Talks
Towards Scalable 3D Reconstruction Models
Adobe, Host: Kalyan Sunkavalli
ByteDance, Host: Jiashi Feng
UC Berkeley, Host: Qianqian Wang, Angjoo Kanazawa
MIT, Host: Visual Computing Seminar
Stanford, Host: Guandao Yang, Leonidas Guibas, Gordon Wetzstein
World Labs, Host: Ben Mildenhall, Justin Johnson
HKU: Yanchao Yang
ENPC of Institut Polytechnique de Paris, Host: Imagine Group
Beijing Academy of Artificial Intelligence (BAAI)
TechBeat Ventures
RayZer: A Self-supervised Large View Synthesis Model
ICCV 2025 Oral Presentation
ICCV 2025 Wild3D workshop
Service
- Area Chair of NeurIPS 2026
- Area Chair of CVPR 2026
- Area Chair of ICLR 2026
- Social Media Chair of 3DV 2026
- Reviewer of CVPR, ICCV, ECCV, ICLR, NeurIPS, ICML, SIGGRAPH, ICRA, 3DV, AAAI, TPAMI, TVCG, RA-L, etc.
- Co-organizer of workshop on 3D in the Era of World Models at ECCV 2026
- Co-organizer of Ind3D workshop CVPR 2025
Honors & Awards
- Best Student Papaer Honorable Mention and Best Paper Candidate, ICCV 2025
- Bert Kay Dissertation Award (Best Thesis Award at UT Austin CS Department) 2025
- CVPR 2025 Doctoral Consortium Selected
- ICLR 2025 Notable Reviewer
- Qualcomm Fellowship Finalist 2025 (with Yuehao Wang)
- UT Graduate Recognition Fellowship
- 3DV 2024 Best Paper Candidate
- Winner of Ego4D VQ2D challenge at CVPR 2024
- IEEE Best Land Transportation Paper Award
- National Scholarship of China (2016 & 2017)
Personal
I am a Chinese Calligrapher (and was one of the best in my generation), my previous undergrad graduation exhibition (2019, in Chinese) is here.
I love table tennis, with rating about 1800.
I am a big fan of Kajiura Yuki.